|
Design a highly distributed data processing pipeline
|
|
|
Overview
It was my intern project in Google Shanghai. I was in the Data
Platform Team, under Advertisement Group in Google Shanghai
Office.
Due to historical reasons, there exists some trivial data
inconsistencies between different Google internal development
teams in India, Shanghai and Mountain View. My task is to
write a highly distributed pipeline to coordiate the data
inconsistency. I adopt
FlumeJava
as the main development framework to process the data and java
as main developmemnt language. In order to handle the error
more gracefully, I also add retrying mechanism and monitoring
services. Finally I deployed it using
Borg
system and it is a
daily run job in Google. It can
process 1.4 billion Google
account data within 20 minutes.
|
|
|
Pipeline Workflow
|
|
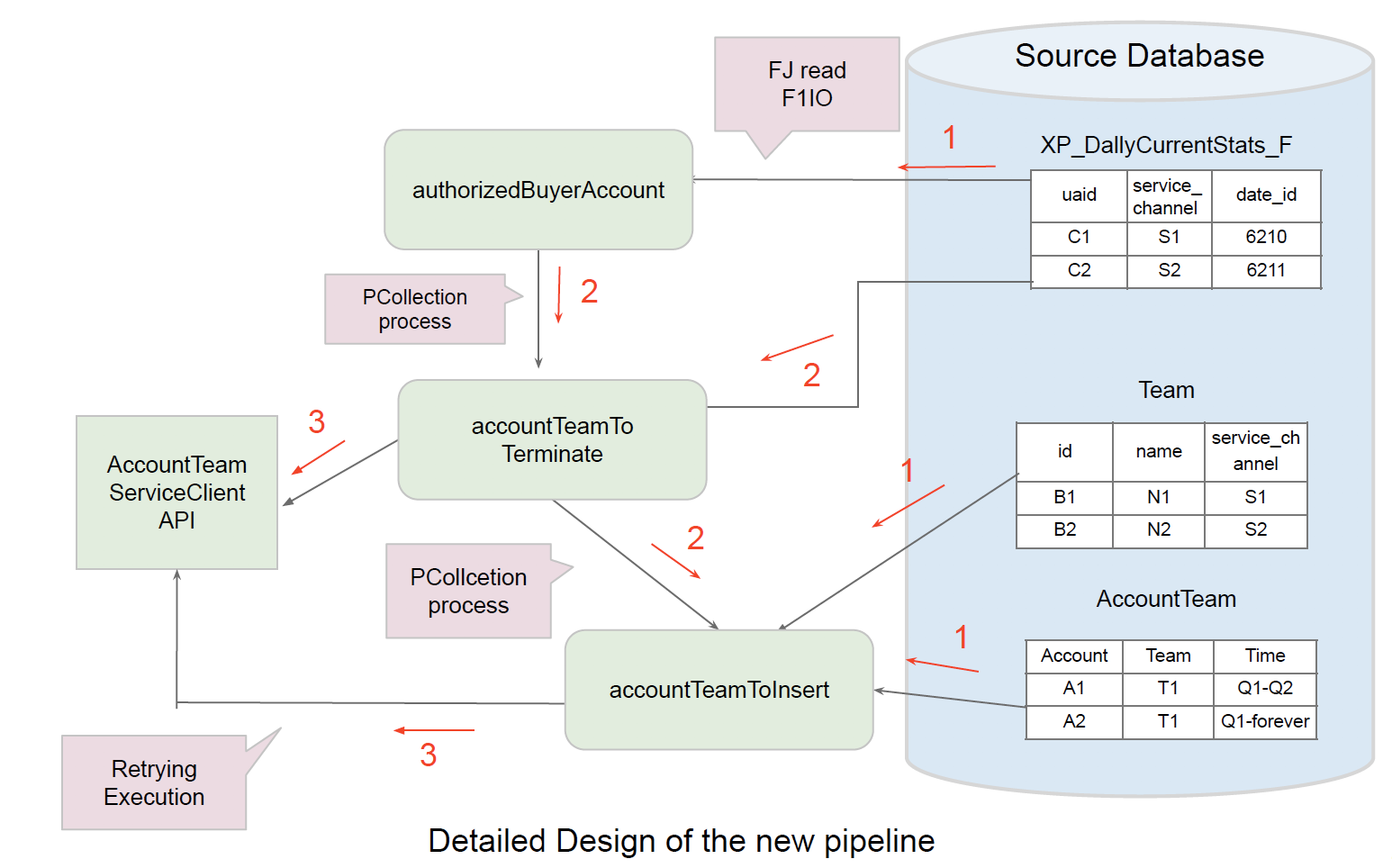
|
|